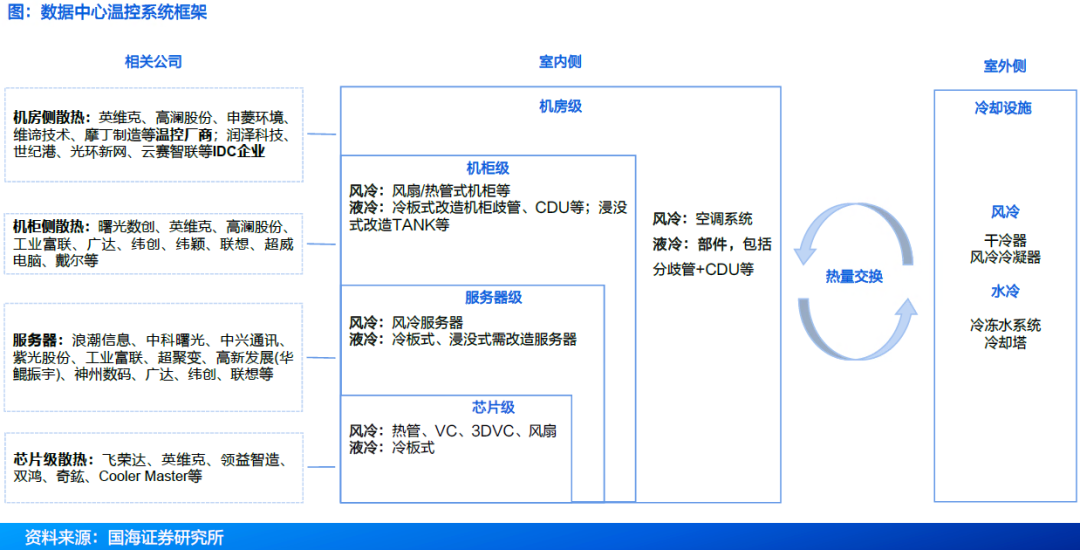
发布时间: 2025-10-21 09:39:14来源:智车行家
Nvidia宣布其首款CPO解决方案,该解决方案将部署在其横向扩展交换机中。CPO将硅光子器件与ASIC封装,取代传统的可插拔光模块在即,与传统网络相比,提升能效3.5倍、部署速度1.3倍。Quantum-X和Spectrum-X交换机减少了对传统光收发器的依赖,为超大规模人工智能工厂提供高达400Tbps的吞吐量。Rubin将采用NVLink 6.0技术,速度翻倍至3.6TB/s。NVLink Fusion向第三方开放互联生态,支持异构芯片协同。新一代NVSwitch 7.0扩展至576颗GPU互联,实现非阻塞通信,实现更大规模的GPU互联。
01
CPO取代可插拔光模块在即,Rubin实现超高速互联
1.1 NVIDIA CPO:集成硅光子技术,打破超大规模与企业网络旧限制
NVIDIA集成硅光子的共封装光纤 ( CPO ) 交换机是面向代理AI时代的全球最先进的网络解决方案。 NVIDIA CPO创新技术将可插拔收发器替换为与ASIC封装在同一封装中的硅光子器件,与传统网络相比,其能效提高了3.5倍,网络弹性提高了10倍,部署速度提高了1.3倍。
根据SemiAnalysis分析,在部署400,000个GB200 NVL72设备的场景中,从传统的基于DSP收发器的三层网络迁移到基于CPO的两层网络,可以实现高达12%的集群总功耗节省,将收发器功耗占比从计算资源的10%降低到仅1%。

NVIDIA CPO:为构建百万级GPU的AI工厂提供保障
NVIDIA CPO带来了多项关键优势,为构建百万级GPU的AI工厂提供了必要的网络可扩展性保障。
ü 功耗方面:CPO技术显著降低网络能耗,相较于传统可插拔光模块,实现3.5倍的能效提升。
ü 网络弹性:在支持自主智能所需的超大规模部署下,相较可插拔光模块提供10倍的网络可靠性与弹性。
ü 部署速度:CPO简化数据中心网络的安装与维护流程,使系统从部署到产生洞察的时间加快1.3倍。
ü 延迟速度:CPO不依赖数字信号处理器(DSP)重定时器,从而显著降低网络延迟。
ü TCO方面:通过消除可插拔光模块的使用,NVIDIA CPO简化了物料清单(BOM),从而降低总体成本。
ü 维修方面:CPO所需组件更少,安装与更换操作远比传统可插拔光模块更为简便。
Nvidia宣布其首款CPO解决方案,该解决方案将部署在其横向扩展交换机中。借助CPO,收发器现在被外部激光源取代,这些激光源与直接放置在芯片硅片旁边的光学引擎 (OE) 一起促进数据通信。光纤电缆现在不再插入收发器端口,而是插入交换机上的端口,将信号直接路由到光学引擎。

1.2 NVIDIA 交换机:力图将AI数据中心功耗降低50%以上
● Nvidia正在通过将CPO集成到其Quantum InfiniBand和Spectrum以太网交换机中来推进其网络技术,此举有望降低AI数据中心的功耗和成本。Quantum-X和Spectrum-X交换机减少了对传统光收发器的依赖,为超大规模人工智能工厂提供高达400Tbps的吞吐量。
● Quantum-X Photonics交换机:上市时间预计在2026年初上市。 NVIDIA Quantum-X800平台正在扩展,新增基于CPO技术的交换机,首款产品为Q3450-LD,支持144个800Gb/s InfiniBand端口。这一突破性交换机采用液冷设计,高效冷却板载硅光子器件。NVIDIA Quantum-X光子InfiniBand交换机支持全新网络架构创新,实现前所未有的扩展能力,可在非阻塞的两级胖树拓扑结构下,以800Gb/s的速率连接超过 10,000 个 GPU。
● 相比Quantum家族的上代产品,速度快2倍,扩展性提升5倍。就Quantum-X系统来看,每颗CPO芯片都配有18个硅光chiplet(3D堆叠的硅光引擎),每个硅光引擎采用TSMC N6工艺,2.2亿晶体管、 1000个集成的光器件;每个硅光引擎连接2个激光器以及16条光纤(一颗CPO芯片也就要连36个激光器、288条数据连接)。
● Spectrum-X Photonics交换机:上市时间预计为2026下半年。 NVIDIA也在其Spectrum-X平台中引入了面向以太网交换机的CPO技术。该系列包括两个型号:一个型号支持512个800Gb/s的以太网端口,另一个型号支持128个800Gb/s的以太网端口。

1.3 NVIDIA NVLink:持续迭代升级,支持纵向扩展的需求
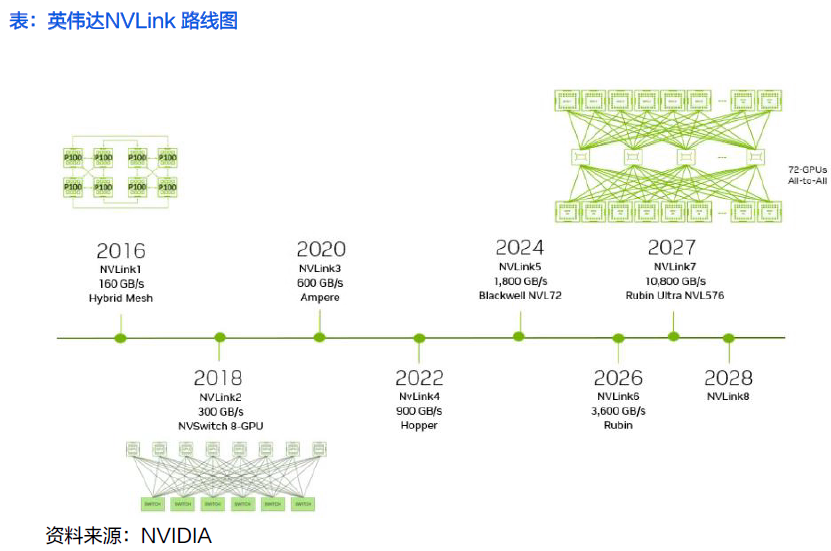
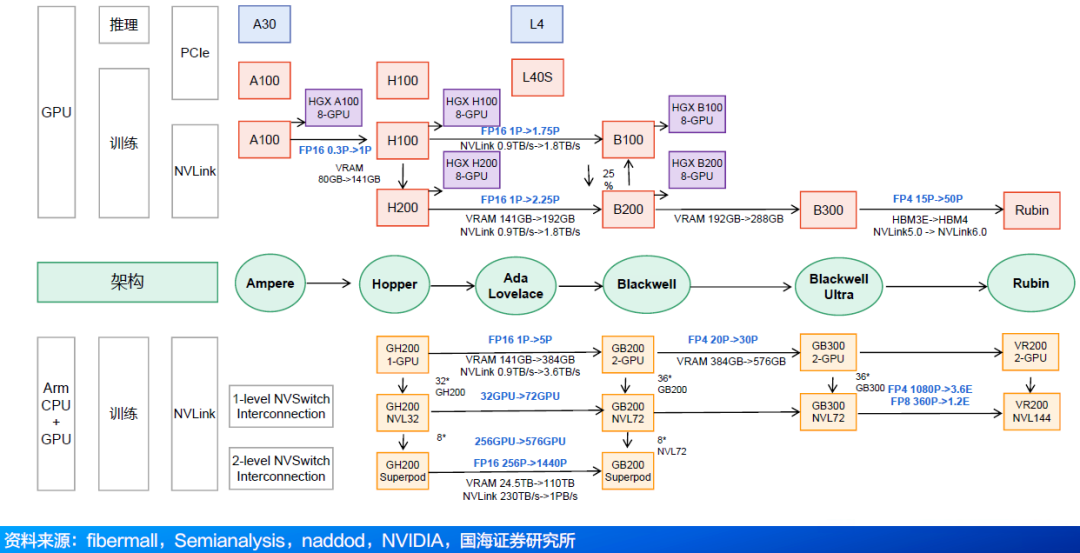
NV Link ——GPU到GPU双向互连技术,可在服务器内扩展多GPU输入和输出 (IO)。NVIDIA保持NV Link年度迭代,不断突破技术极限,对未来三代的NVLink产品,会保持每年推出一代的节奏。这一迭代策略推动了持续的技术进步,有效满足了AI模型在复杂性和计算需求方面的指数级增长。
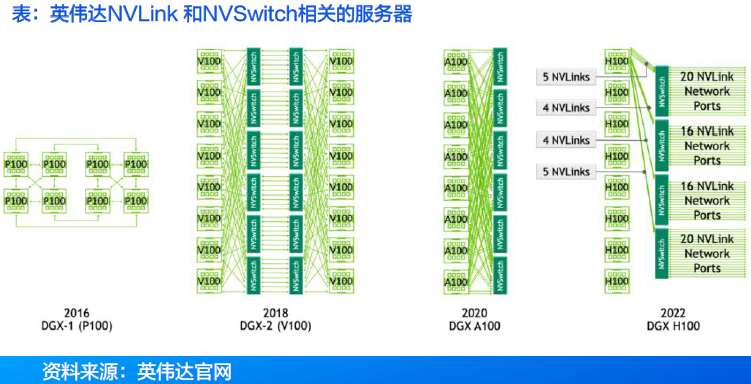
2016年,NVIDIA首次推出NVLink,旨在克服PCIe在高性能计算和人工智能工作负载中的局限性。该技术实现了更快的GPU间通信,并构建了统一的内存空间。
2018年,NVIDIA推出了NV Link Switch技术,实现了在8个GPU的网络拓扑中每对GPU之间高达300GB/s的all-to-all带宽,为多GPU计算时代的 scale-up网络奠定了基础。 随后,在第三代NVLink Switch中引入了NVIDIA可扩展分层聚合与归约协议(SHARP)技术,进一步提升了性能,有效优化了带宽性能并降低了集合操作的延迟。
2024 年,第五代 NVLink 发布,进一步增强的NVLink Switch支持7 2个GPU实现全互联通信。通信速率达1800GB/s , 聚合总带宽高达130TB/s,较第一代产品提升了800 倍。
2026年,Rubin将采用NVLink6.0技术,速度翻倍至3.6TB/s(双向)。
1.4 NVIDIA NVLink Fusion:开放半定制设计,满足客户的灵活需求
NVIDIA NVLink Fusion——全新互联芯片,构建半定制AI基础设施。2025年5月19日,NVIDIA发布NVLink Fusion,旨在向第三方CPU和加速器开放NVLink生态系统,通过发布IP和硬件推动第三方设计与自家芯片互操作,虽系统仍需包含部分NVIDIA芯片,但目标是让合作伙伴构建融合英伟达芯片与定制芯片的半定制机架系统。
NVLink Fusion的优势:
ü 出色的纵向扩展性能:要充分发挥AI工厂的潜力,关键在于每个加速器之间需要快速、无缝的通信。NVIDIA NVLink 1.8TB/s 互连速度可扩展至72个加速器,助力释放AI性能。
ü 强健的生态系统:NVIDIA生态系统合作伙伴 ( 包括ASIC设计师、CPU和 I P提供商以及OEM/ODM ) 助力超大规模企业借助NVLink Fusion部署定制芯片,并缩短上市时间。
ü 易于部署和管理:超大规模数据中心已经部署完整的NVIDIA机架解决方案,NVLink Fusion支持异构芯片产品,同时围绕通用机架设计实现标准化,加速AI工厂部署并简化管理。
ü 持续迭代性:NVIDIA保持年度路线图节奏,确保为NVLink Fusion采用者提供高性能的NVLink和整机柜架构性能。

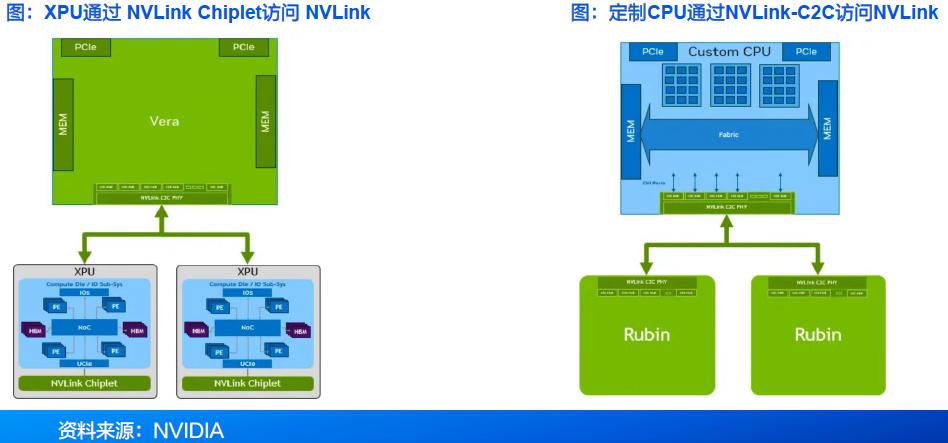
NVLink Fusion为定制CPU、定制XPU或两者的组合配置提供了灵活的解决方案。作为模块化开放计算项目(OCP)MGX机架架构的一部分, NVLink Fusion可与任何网卡(NIC)、数据处理器(DPU)或横向扩展交换机集成,使客户能够根据需求灵活构建理想的系统。
对于定制XPU配置,NVLink通过通用芯粒互连(UCIe)IP与接口实现集成。NVIDIA提供支持UCIe的NVLink桥接芯片,既能实现极高性能,又便于集成,使客户能够像 NVIDIA 一样充分利用NVLink的功能。UCIe作为一项开放标准,采用该接口进行NVLink集成可让客户为其XPU灵活选择当前或未来平台的多种方案。
对于定制CPU配置,建议集成NVIDIA NVLink-C2CIP,以连接NVIDIA GPU,从而实现最佳性能。采用定制CPU与NVIDIA GPU的系统可平滑访问CUDA平台的数百个NVIDIA CUDA-X 库,充分发挥加速计算的高性能优势。
1.5 NVIDIA NVL72:优化铜缆布局,预计线缆长度将增加50%
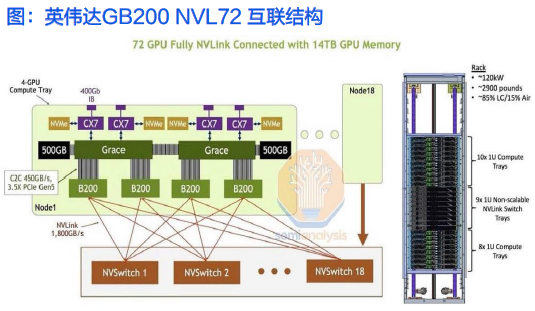
● 英伟达GB200NVLink Switch和Spine由72个Blackwell GPU采用NVLink全互连,有5000根NVLink铜缆(合计长度超2英里)。GB300进一步优化了铜缆布局,预计线缆长度将增加50%,以满足更高性能和更大数据传输需求。
● 作为新一代AI服务器,GB300标配支持1.6T光模块(800 G×2)的CX 8网卡,对内部数据传输带宽要求较高。机柜内短距离互联场景(< 5米)需要低时延、低功耗、高密度布线,1.6T铜缆(DAC或AEC)是最佳技术方案。这些铜缆单通道速率高达224Gbps,能够满足多通道聚合带来的高带宽需求。

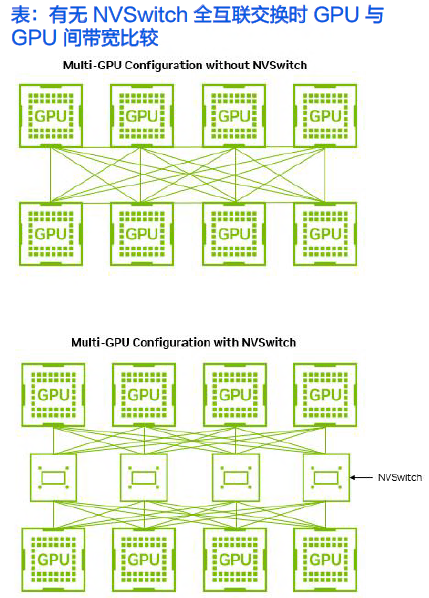
1.6 NVIDIA NVSwitch:实现非阻塞通信,实现更大规模的GPU互联
NVSwitch——基于NVLink的多GPU互联解决方案。它不仅支持更多的NVLink链路,还允许多个GPU之间实现全互联,较大地优化了数据交换的效率和灵活性。
NVIDIA将推出一款全新的NVSwitch 7.0。这是新款NVSwitch首次应用于中端平台。这允许更大的交换机聚合带宽和基数,从而在单个域中扩展至576个GPU芯片(144个封装),尽管拓扑结构可能不再是全对全无阻塞、轨道优化的单层多平面拓扑。相反,它可能是一个多平面轨道优化的双层网络拓扑,具有超额认购,甚至是非封闭拓扑。
02
GB300计算能力大幅提升,Rubin预期乐观
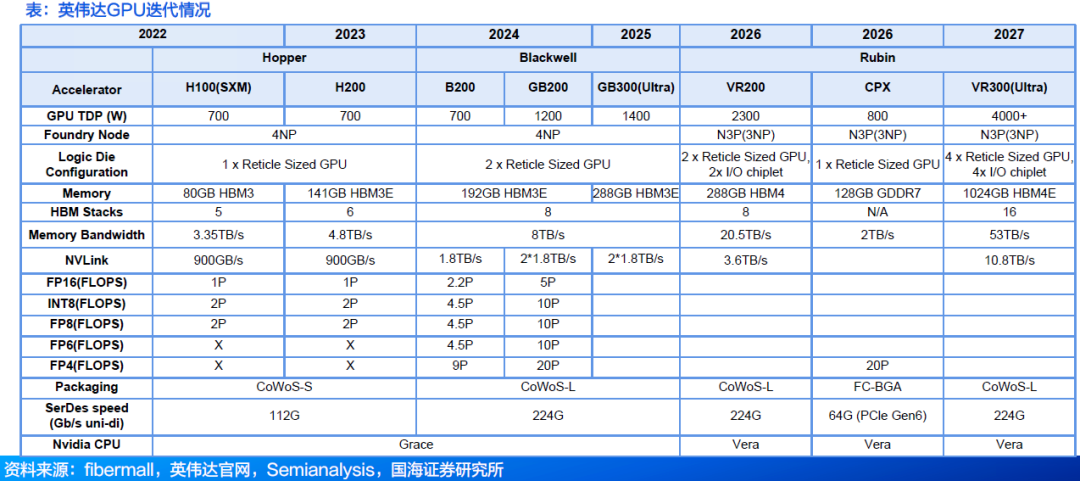
2.1 NVIDIA每一代GPU的计算能力、NVLink、内存持续扩大
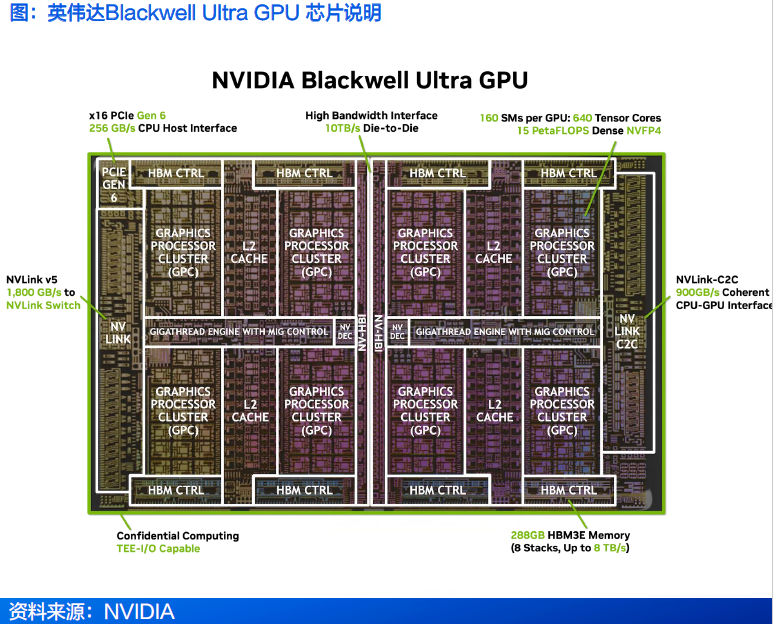
英伟达Blackwell Ultra凭借节能的双光罩(dual‑reticle)设计、高带宽大容量HBM3E内存子系统、第五代Tensor核心以及突破性的NVFP4精度格式,正在提升加速计算的新标准。
2.2 B300:Blackwell Ultra为TSMC 4NP工艺,内存容量扩大
B300 GPU:
计算性能:基于新一代Blackwell Ultra架构,采用TSMC的4NP定制工艺,搭配NVIDIA的CoWoS-L封装技术。FP4浮点算力可达1 5 P F L O P S,比B 2 0 0的FLOPS提升50%,部分性能提升将来自200W的额外功耗。
内存容量 : 从8-Hi升级到了12-Hi HBM3E,使得每个GPU的内存容量增加到了288GB,不过由于引脚速率保持不变 , 单GPU的内存带宽仍维持在8TB/s。
高效网路互联:引入ConnectX-8NIC,该NIC提供4个200G通道,为InfiniBand实现800G的总吞吐量,与当前的Blackwell CX-7NIC相比,网络速度提高了一倍。
2.3 GB300:采用HBM3E技术,FP4的计算能力实现1.5倍的增长
GB300性能:集成更强大的B300芯片并采用12层堆叠HBM3 E显存,总容量288GB(较前代192 GB大幅提升),带宽保持8TB/s;FP4计算能力相比前代产品提升1.5倍,显著增强AI大规模浮点运算性能。
GB300结构:通过NVLink-C2C 将一个Grace CPU与两个 Blackwell Ultra GPU连接,支持NVLink5.0,每个GPU双向带宽1.8TB/s;内置ConnectX‑8 SuperNIC,提供800Gb/s高速网络并拥有48条PCIe通道;支持新的架构如空气冷却MGX B300A。对于GB300,Nvidia不再提供完整的Bianca板,而是转而供应B300作为SXM Puck模块,Grace CPU则以BGA封装形式提供。转向SXM Puck为更多OEM和ODM参与计算托盘提供了机会。
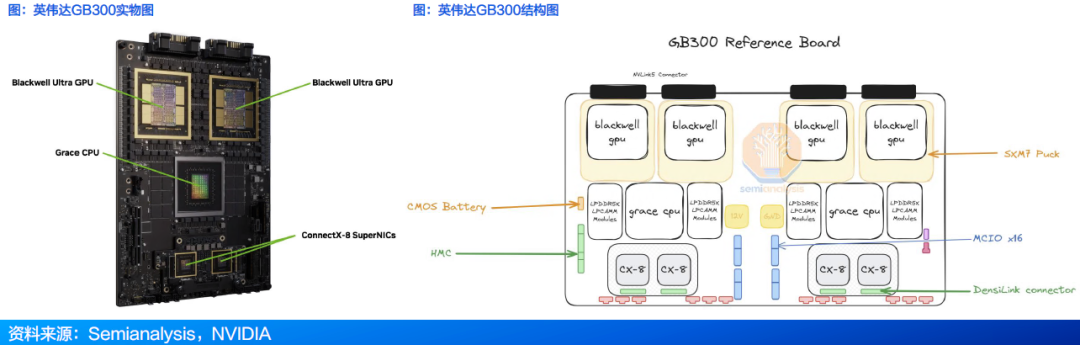
2.4 2026年推出Rubin架构,继任者Feynman于2028年登场
● 2026年将推出Rubin架构,基于Rubin的Vera Rubin NVL144机柜由72颗Vera CPU和144颗Rubin GPU组成。
● 2027年推出Rubin Ultra 产品 , 基于Rubin Ultra的Rubin Ultra NVL 576配备576颗 Rubin Ultra GPU组成。
● 2028年将推出Feynman架构。
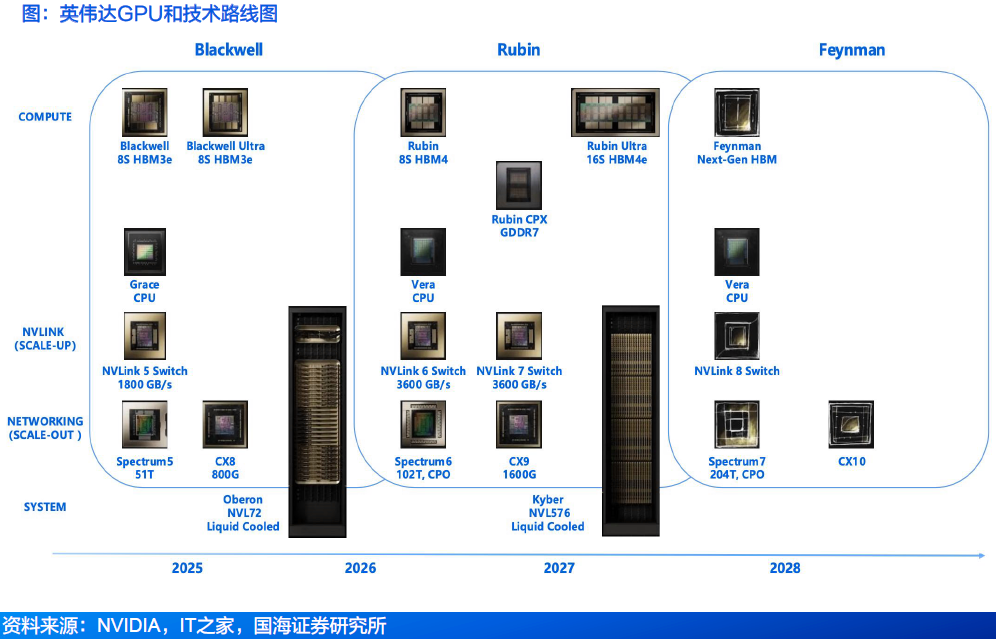
2.5 NVIDIA Dynamo:提升多GPU推理效率,AI工厂的操作系统
● NVIDIA Dynamo——开源、低延迟的模块化推理框架,在分布式环境中服务生成式AI模型。Dynamo可在多个GPU节点之间扩展推理任务,并动态分配GPU工作线程,以缓解流量瓶颈。Dynamo还支持解耦式推理服务,可将大型语言模型推理中的上下文预填(prefill)与生成(decode)阶段在多个GPU间分离执行,以优化性能、提升可扩展性并降低成本。
● NVIDIA Dynamo解决了分布式和分解推理服务的挑战。它包括四个关键组件:
GPU资源规划器:一个规划和调度引擎,用于监控多节点部署中的容量和预填充活动,以调整GPU资源,并在预填充和解码之间分配这些资源。
智能路由:KV缓存感知路由引擎,可在多节点部署中高效引导大型GPU集群中的传入流量,从而最大限度地减少昂贵的重新计算。
低延迟通信库:先进的推理数据传输库,可加速GPU之间以及异构内存和存储类型之间的KV缓存传输。
KV缓存管理器:成本感知型KV缓存卸载引擎,旨在跨各种内存层次结构传输KV缓存,在保持用户体验的同时释放宝贵的GPU内存。
● Dynamo的智能推理优化可将每个GPU生成的token数量提高30倍以上。基于Dynamo,相比Hopper,Blackwell性能提升25倍,可以基于均匀可互换的可编程架构。在推理模型中,Blackwell性能是Hopper的40倍。
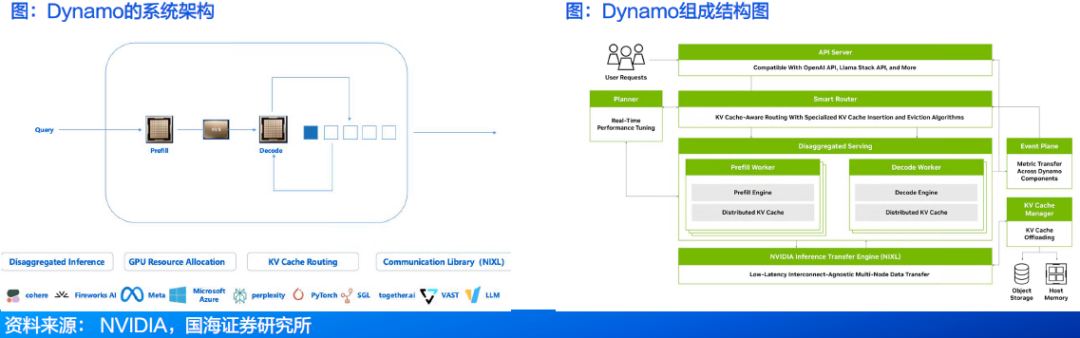
2.6 CUDA:NVIDIA的GPU并行计算生态与架构
● CUDA是NVIDIA开发的一个并行计算平台和编程模型,用于在GPU上进行通用计算。借助CUDA,开发者能够利用GPU的强大功能显著加快计算应用程序的运行速度。
● CUDA主要包含两个关键组成部分:1)Toolkit:作为编译器,负责高效的编译功能 2)驱动器:支撑CUDA在硬件上的运行。
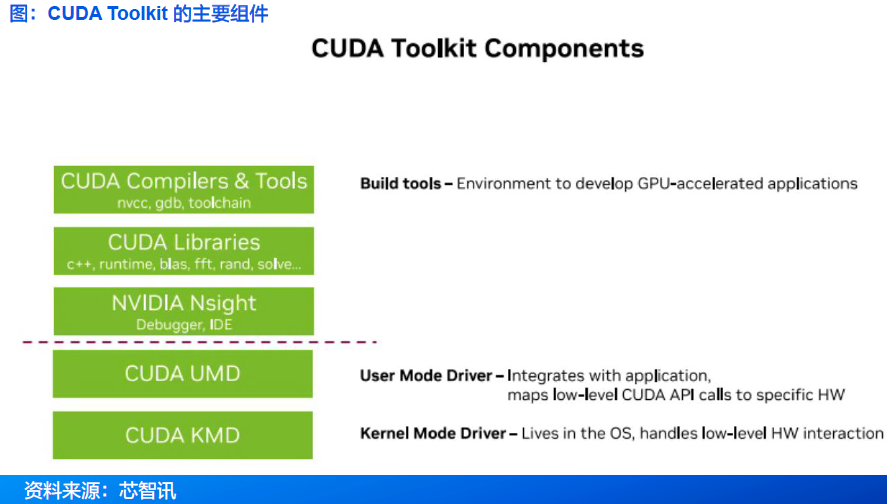
• CUDA的复杂性不断扩大,涵盖驱动程序、语言、库和框架的多层生态系统。
• CUDA平台的核心包括:
• 庞大的代码库:数十年优化的GPU软件,涵盖从矩阵运算到AI推理的所有领域。
• 庞大的工具和库生态:从用于深度学习的cuDNN到用于推理的TensorRT, CUDA涵盖了广泛的工作负载。
• 硬件调整性能:每个CUDA版本都针对NVIDIA最新的GPU架构进行深度优化,确保顶级效率。
• 专有且不透明:当开发者与CUDA的库API交互时,底层发生的很多操作都是闭源的,并且与英伟达的生态系统紧密相连。
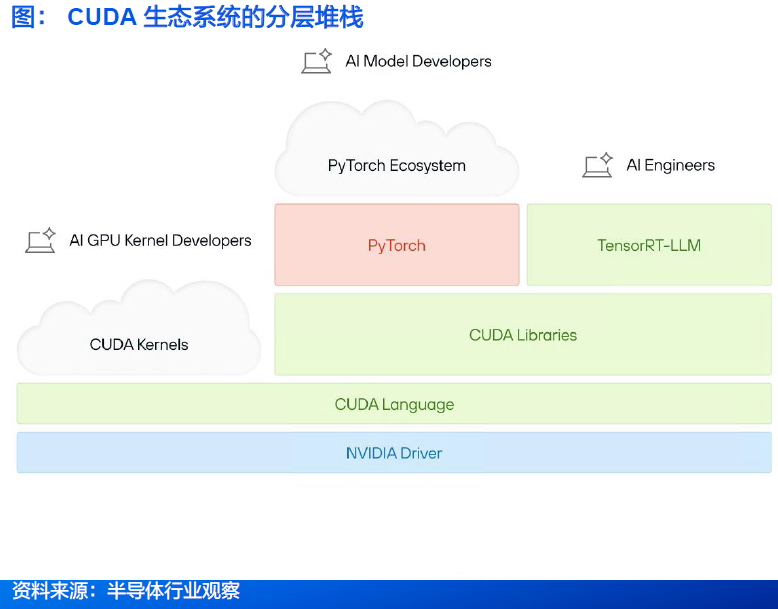
CUDA:Blackwell与CUDA - X 驱动半导体制造革新
● 台积电、Cadence 、KLA、西门子和Synopsys正在采用NVIDIA CUDA-X和NVIDIA Blackwell平台推动半导体制造的发展。
● NVIDIA Blackwell GPU、NVIDIA Grace CPU、高速NVIDIA NVLink结构和交换机以及特定领域的NVIDIA CUDA-X库(如NVIDIA cuDSS和NVIDIA cuLitho)正在改进先进芯片制造的计算光刻和设备模拟。

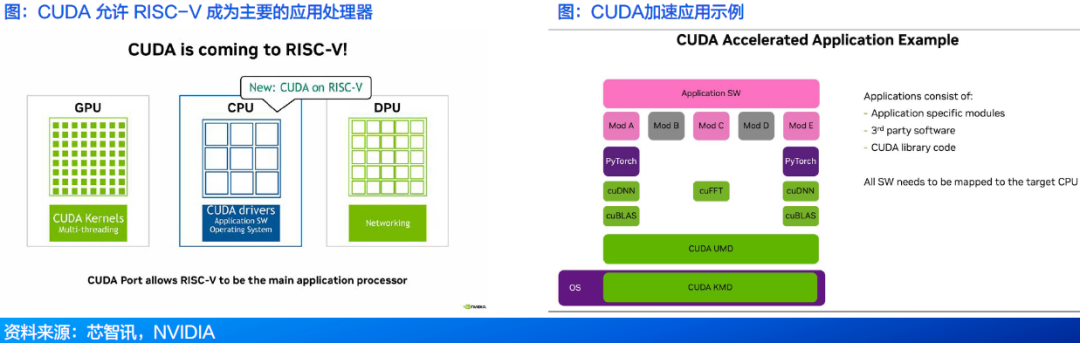
CUDA:支持RISC-V,生态系统拓展至开源领域
● 在2025年RISC-V峰会上,英伟达宣布其CUDA软件平台将在CPU方面兼容R ISC-V指令集架构(ISA)。
● 会议上展示的图表展示了一种典型的配置:
ü GPU处理并行工作负载,而RISC-V CPU执行CUDA系统驱动程序、应用程序逻辑和操作系统。这种设置使CPU能够完全在CUDA环境中协调GPU计算。
ü 图中还展示了一个处理网络任务的DPU,完善了由GPU计算、CPU编排和数据移动组成的系统。这种配置清晰地展现了NVIDIA构建异构计算平台的愿景,其中RISC-V CPU可以作为管理工作负载的核心,而NVIDIA的GPU、DPU和网络芯片则负责处理其余部分。
以一个完整的CUDA加速应用示例,包括特定应用模块、第三方软件、CUDA库代码,所有软件都需要映射到目标CPU。目前CUDA的重点移植的是下图中的绿色部分(如PyTorch示例中的CUDA KMD、CUDA UMD)此外,第三方软件和应用软件也需同步移植到RISC-V。
03
主板从HGX到MGX ,Rubin Ultra NVL576架构升级
3.1 英伟达整机:HGX到MGX计算平台,服务器整机到系统形态
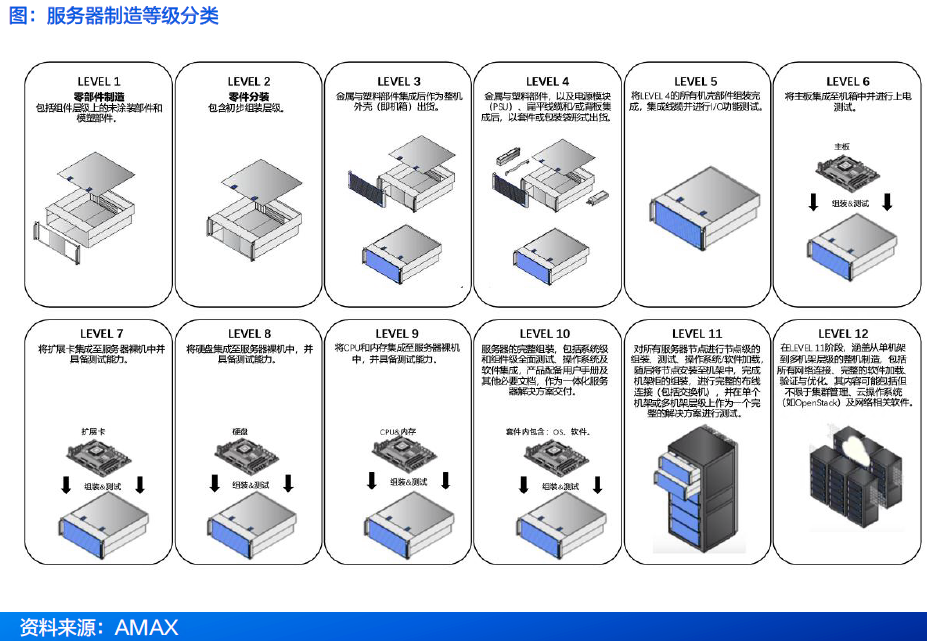
服务器制造级别可分为Level1-Level12 。 Level 1为零部件制造, Level 6为主板集成,通常为 ODM 发货“服务器准系统”时提供的。 Level10为完整服务器组装和测试,能够达到10 级制造水平的制造商将提供有效的服务器解决方案。Level11-12级可将多台服务器联网作为机架级甚至多机架级解决方案。
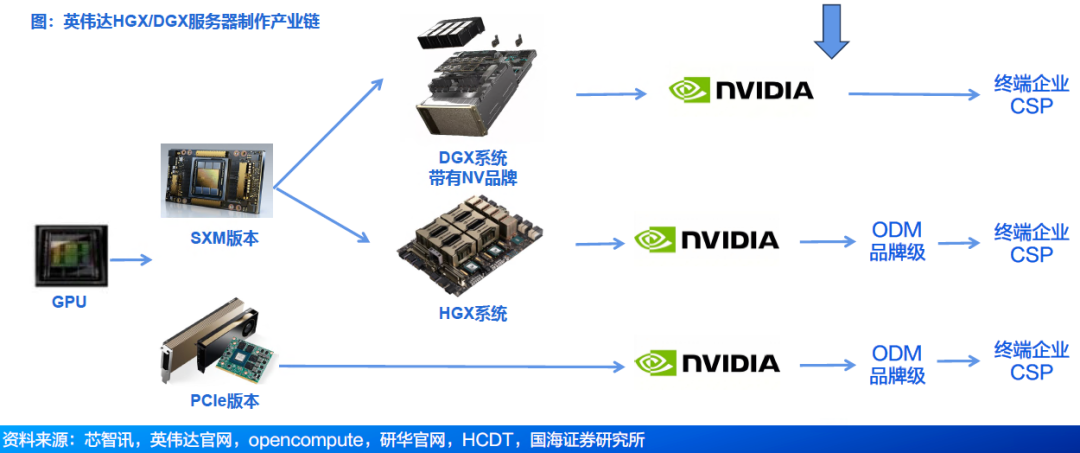
3.2 英伟达整机:HGX版本由ODM出货,DGX版本由英伟达交付
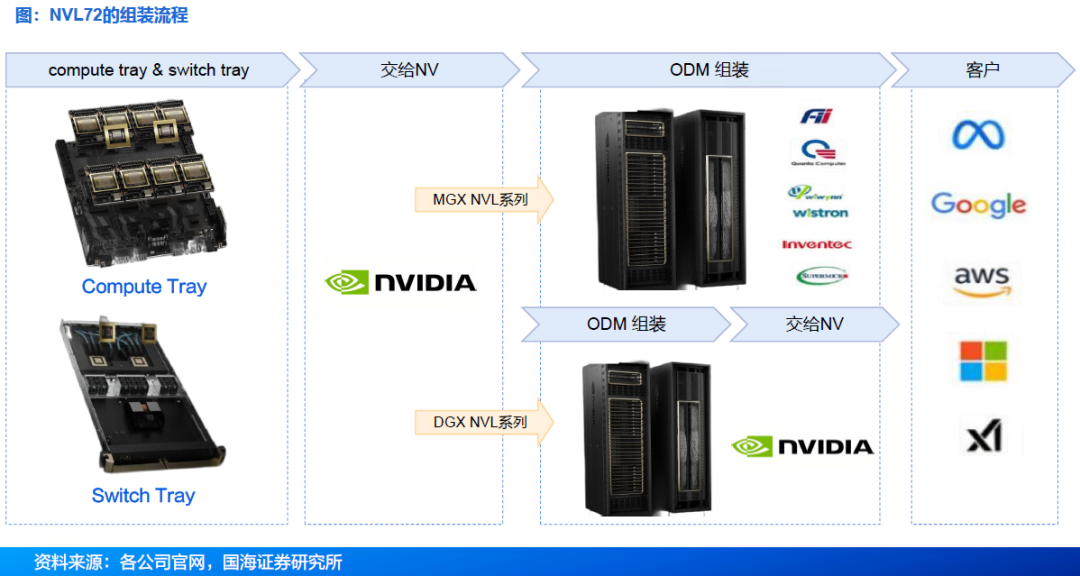
● HGX:模组主要为SXM版本,随后8个GPU SXM模组构建成一个HGX UBB基板,基本交付给英伟达后,分配给品牌级服务器厂商,包括鸿海、广达、纬创、英业达等厂商。
● DGX:SXM模组生产后,交给下游服务器厂商进行组装,整机交付给英伟达,流向下游CSP厂商与企业客户等。
3.3 英伟达整机:MDX开放模块化设计,NVL 72或采用此结构
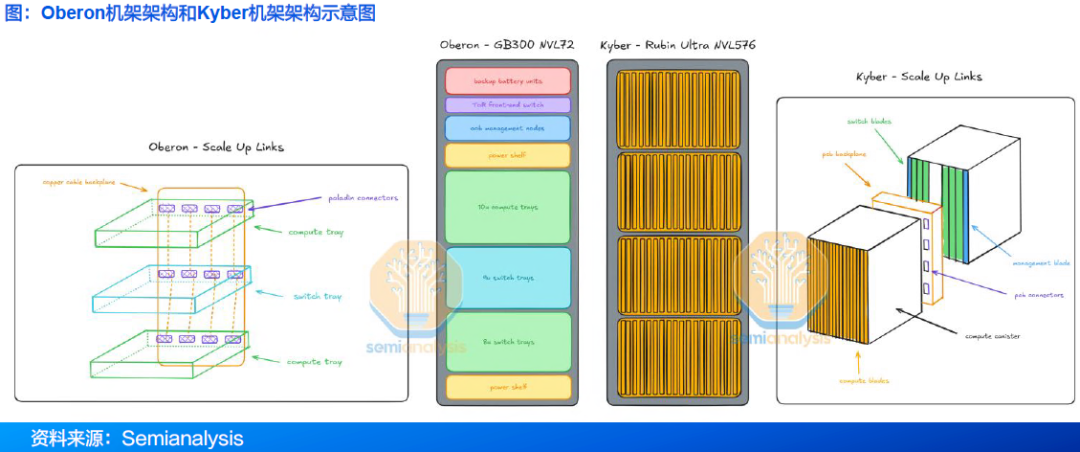
MGX(Modul e GPU Accel erator):是一个开放模块化服务器设计规范和加速计算的设计。MGX让系统制造商快速且经济高效地为AI、HPC和 NVIDIA Omniverse 应用程序构建100多种服务器变体。 GB300 NVL72整个系统由18个计算托盘和9个交换机托盘组成。

3.4 英伟达整机:GB300 NVL72提升性能与带宽,显著增强AI工厂效率
ü GB300 NVL 72机架:18个计算托盘,每个计算托盘包含4颗Blackwell Ultra GPU+2颗Grace CPU,总计72颗Blackwell Ultra GPU+36颗Grace CPU;HBM容量达到了20TB,总带宽576 TB/s ;配备9个NVLink 交换机托盘;节点间NVLink带宽130TB/s ;内置72张CX-8 网卡,提供 14.4TB/s带宽。 GB300 NVL72可无缝集成NVIDIA Quantum - X800与NVIDIA Spectrum-X网络平台,使 AI 工厂和云数据中心能够从容应对三大扩展定律的需求。此外,机架还整合了18张用于增强多租户网络、安全性和数据加速Blue Field- 3 DPU。
ü NVIDIA Blackwell Ultra 与 Hopper 相比AI工厂输出性能的整体潜力提升5 0倍。与 Hopper 相比,采用NVIDIA GB300 NVL 72的A I工厂将在每用户T PS上实现10倍提升,并在单位功耗(每MW)吞吐率上相比Hoppe r架构实现5倍提升。这一叠加效应将带来AI工厂总体产出性能最多提升50倍的潜力。

3.5 NVL 72组装模式:计算能力、内存容量实现提升
● GB300 NVL72对比GB200 NVL72
ü 计算性能:密集FP4计算提升至1.5倍,INT8计算几乎被淘汰 : GB200提供 360P(INT8稀疏计算),而GB300 则降至仅23P( INT8密集计算)。
ü 内存配置:HBM内存 ( 容量增加1.5倍,带宽保持为每个GPU8TB/s)。
• GB200: 72个GPU x 192GB =总计13.8TB。
• GB300 : 72个GPU x 288GB =总计20.7TB。
ü 互联网技术:内置全新的ConnectX-8网卡,替代了之前的ConnectX-7,同时光模块带宽从800G升级到了1.6T,这一改进显著提升了数据传输速度和网络带宽。
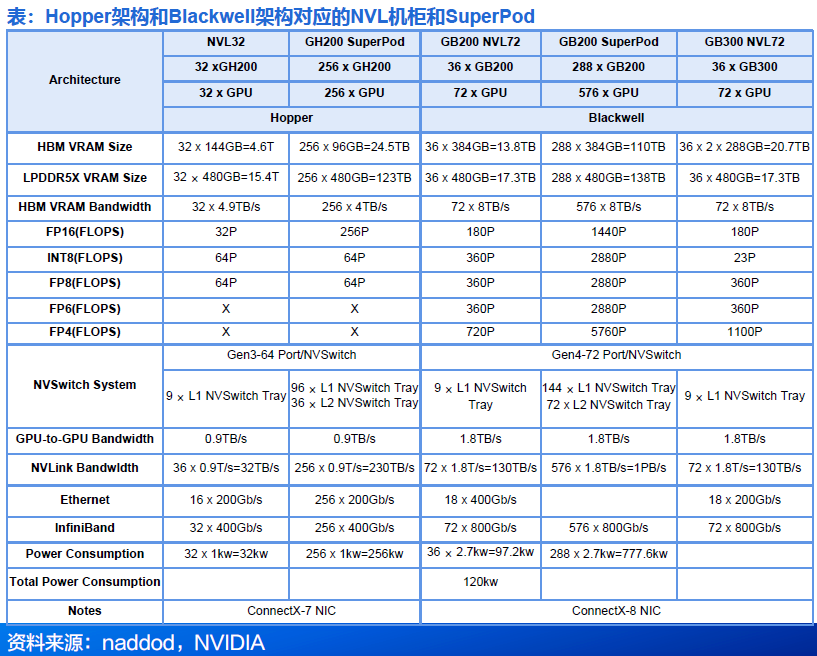
3.6 NVL 72组装模式:优化PCB与机架设计,提升互联性能
● PCB:全称Printed Circuit Board,即印刷电路板,是指在通用基材上按预定设计形成点间连接及印制元件的印刷板。
● Rubin Ultra NVL576采用Kyber架构,PCB背板替代铜缆互联。英伟达将于2027年下半年推出Rubin Ultra NVL576产品,使用代号为“Kyber”的新型液冷机架。在此架构下,计算托盘被旋转90度,显著提升机架密度。每个机架包含4个计算单元,每层配置18个计算刀片。为了克服在有限空间中布设铜缆的难度,PCB板背板取代了铜缆背板,作为机架内GPU与NVSwitch之间的扩展互联链路。
3.7 Vera Rubin NVL 144:配备HBM4内存,算力与互连全面升级
Vera Rubin NVL144将于2026年下半年推出。
规格:Rubin GPU将采用两颗Reticle大小的芯片,FP4性能高达50 PFLOPS,并配备288 GB的HBM4内存。这些芯片还将搭载一颗88核Vera CPU,该CPU采用定制的Arm架构,拥有176个线程,并支持高达1.8 TB/s的NVLINK-C2C互连。
性能扩展:Vera Rubin NVL 144 平台将具有3.6Exaflops 的FP4推理能力和1.2Exaflops的FP8训练能力,比GB300 NVL72提升3.3倍,13TB/s的HBM4内存和75TB的快速内存,比GB300提升60%,并且NVLINK和CX 9功能是前代的2倍 ,额定速度分别高达260TB/s 和28.8TB/s。

3.8 Vera Rubin Ultra NVL 576:配备HBM4 E内存,性能显著跃升
Vera Rubin Ultra NVL576计划2027年下半年推出。
规格:Rubin Ultra GPU将配备四个Reticle-Sized GPU,提供高达100 PFLOPS的FP4性能,并配备1TB的HBM4E内存。
性能扩展:Rubin Ultra NVL576平台将具有15Exaflops的FP4推理能力和5Exaflops的FP8训练能力,比GB300 NVL72 提升14倍 ;4.6PB/s的HBM4E内存和365TB的快速内存,是GB300的8倍;NVLINK能力是前代的12倍,CX9能力是前代的8倍 , 额定速度分别高达1.5PB/s和115.2TB/s。

3.9 NVL 72组装模式:MGX - - >整机柜- - >集群
04
HBM4预计2026年实现量产,SK海力士主导HBM市场
4.1 HBM市场:预计制造难度更高的HBM4溢价幅度将突破30%
● HBM(High Bandwidth Memory):是一款新型的CPU/GPU内存芯片(即“RAM”),是将很多个DDR芯片堆叠在一起后和GPU封装在一起,实现大容量,高位宽的DDR组合阵列。
● 根据TrendForce最新研究,HBM技术发展受AI Server需求带动,三大原厂积极推进HBM4产品进度。由于HBM4的I/O(输入/输出接口)数增加,复杂的芯片设计使得晶圆面积增加,且部分供应商产品改采逻辑芯片架构以提高性能,皆推升了成本。据Trendforce数据,鉴于HBM3E刚推出时预计的溢价比例约为20%,预计制造难度更高的HBM4溢价幅度将突破30%。
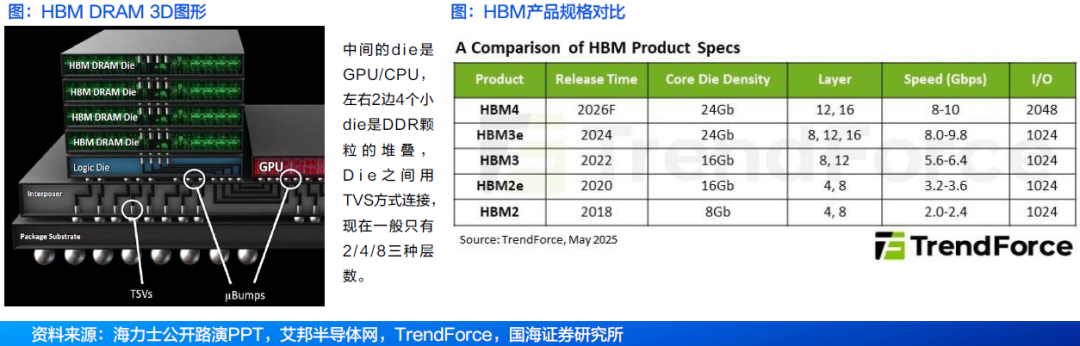
4.1 HBM市场:HBM4预计于2026年推出,自2026年起开始量产
HBM4预计规划于2026年推出,预计将在2026年第二季度量产。HBM迭代快速,集邦咨询预计HBM3E将占据2025年出货份额超过90%,2026年HBM4将开始渗透入市场,供货商预计2026年第二季度量产。随着客户对运算效能要求的提升,在堆栈的层数上,HBM4除了现有的12hi外,也将再往16hi发展。
HBM4 12hi产品将于2026年推出;而16hi产品则预计于2027年问世。此外,受到规格更往高速发展带动,将首次看到HBM最底层的Logic die采用12nm制程wafer,该部分将由晶圆代工厂提供,使得单颗HBM产品需要结合晶圆代工厂与存储器厂的合作。

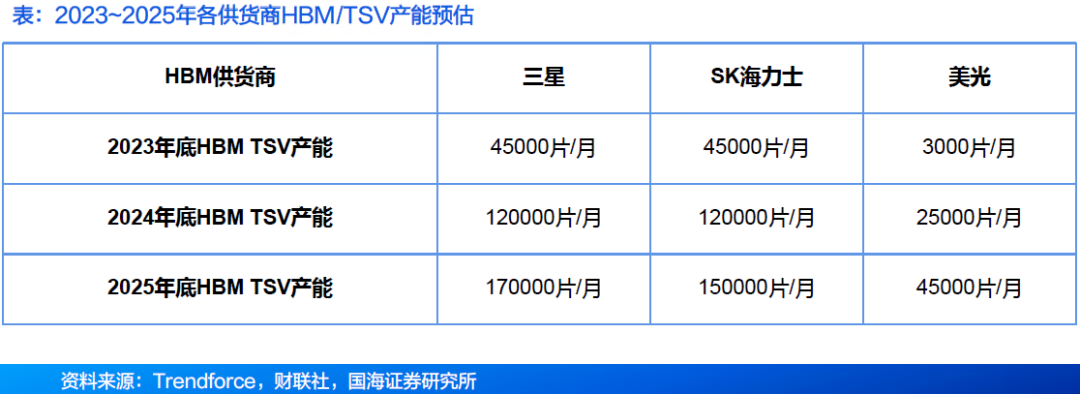
4.2 HBM:预计2025年三星产能领先,SK海力士市占超50%主导H BM市场
● 以HBM产能来看,三星、SK海力士(SK hynix)至2025年底的HBM产能规划较为积极,三星HBM总产能至年底将达约170K(含TSV);SK海力士约150K,但产能会依据验证进度与客户订单持续而有变化。
● Counterpoint Research表示,SK海力士扩大了其在HBM领域的领先地位,第一季度市场份额达到70%。TrendForce预测,今年SK海力士的HBM市场份额将保持在50%以上,三星的份额将降至30%以下,美光科技的份额将升至近20%。
4.3 HBM:定制化HBM直击AI时代需求,预计2025年下半年实现
● SK海力士领跑定制化HBM4E。SK海力士已与NVIDIA、微软与博通展开合作,设计客户专属的定制化HBM芯片。首批商用定制HBM产品预计将于2025年下半年出货。SK海力士此前曾表示,从HBM4E开始,将全面转向定制化生产模式。当前主流为第五代HBM3E,产业正加速迈向第六代HBM4。为支撑该转型,SK海力士已与台积电合作代工逻辑HBM堆栈中的“核心大脑”。
● HBM4逻辑基片设计定制化,提升AI性能与功耗效率。据TrendForce称,目前的HBM3基础芯片采用纯内存架构,仅充当信号通路。相比之下,SK海力士和三星正在与代工厂合作,为HBM4采用基于逻辑的基片设计。这种新方法使HBM与SoC之间能够更紧密地集成,从而降低延迟、提高数据路径效率,并在高速传输环境中提供更高的稳定性。定制化HBM旨在满足AI时代日益复杂的性能与功耗效率需求,尤其是当超大规模客户逐步从通用内存迁移至针对AI工作负载优化的专属模组。

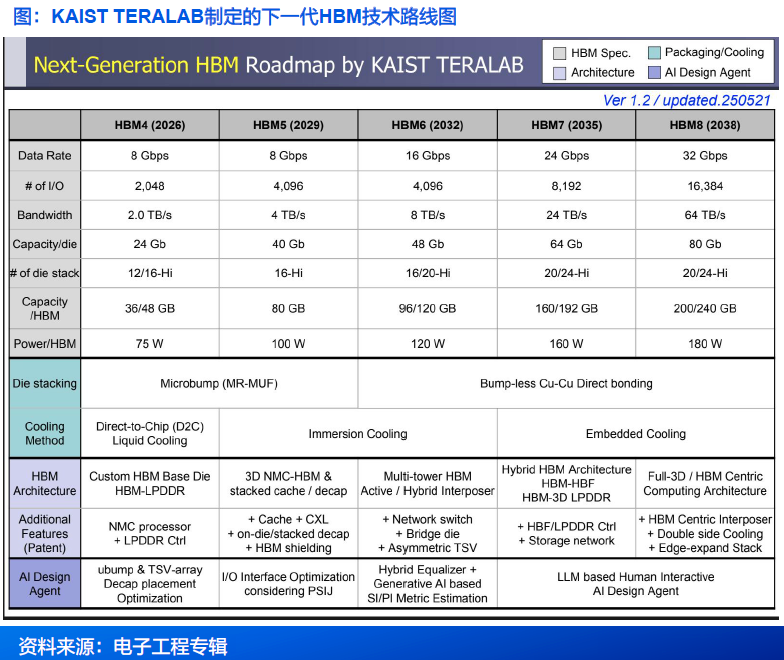
4.3 HBM:KAIST发布技术演进路线,展望未来发展方向
● 2025年6月,韩国国家级研究机构——韩国科学技术院(KAIST)发布HBM相关论文,详细介绍了HBM技术到2038年的演进,展示了带宽、容量、 I/O 宽度和散热性能的提升。该路线图涵盖了从HBM4 到HBM8的技术发展,涵盖了封装、3D堆叠、以内存为中心的嵌入式NAND存储架构,甚至还有基于机器学习的功耗控制方法。
● HBM性能参数全面跃升:容量、功耗、带宽与接口技术持续突破。在容量方面,预计单堆栈容量将从HBM4的288-348GB跃升至HBM8的5,120-6,144GB;功耗管理上,单堆栈功耗将随性能提升从75W(HBM4)增至180W(HBM8),并配套机器学习动态调频技术;带宽性能方面,预计2026年至2038年间,内存带宽将从2TB/s增长到64TB/s,数据传输速率将从8GT/s提升到32GT/s。每个HBM封装的I/O宽度也将从目前HBM3E的1,024位接口增加到HBM4的2,048位,之后将一路提升到HBM4的16,384位。
05
冷板式液冷较为成熟,GB300采用液冷方案
5.1 芯片散热革新:相比热管/ VC / 3DVC,冷板式散热范围广
● 随着芯片功耗的提升,从一维热管的线式均温,到二维VC的平面均温,发展到三维的一体式均温,即3D VC技术路径,最后发展到液冷技术。
● 热管与VC的散热能力较低,3D VC风冷散热上限扩大至1000W,冷板式具备1000W+的广阔散热范围。
2026年GPU液冷市场有望达800亿元
● GB200/GB300出货量的扩大使液冷渗透率不断提升,液冷市场空间大开。TrendForce预估今年Blackwell GPU将占NVIDIA高阶GPU出货比例80%以上,随着GB200/GB300出货的扩大,液冷散热方案在高阶AI芯片的采用率正持续升高。按照单机柜液冷价值量70万元计算,假设明年出货10-12万个机柜,我们预计仅GPU液冷市场就有望达800亿。以Global Market Insights 2024年规模数据65亿美元为基准,2025-2026年CAGR约为30%。
● 非GPU/CPU部分也存在散热需求,整体制造成本有望显著提高。英伟达计划2027年推出的Rubin Ultra NVL576——600kW等级的Kyber机架,将彻底摒弃风冷,实现100%液冷,并采用计算刀片(compute blade)。(国海证券研究所)